

4 min read
Build vs Buy AI: When to Partner for Implementation
AK
TL;DR
The failure is rarely at the model. Most internal AI builds stall at annotation inconsistency or the production deployment gap — stages that look simple on a roadmap and quietly absorb six months.
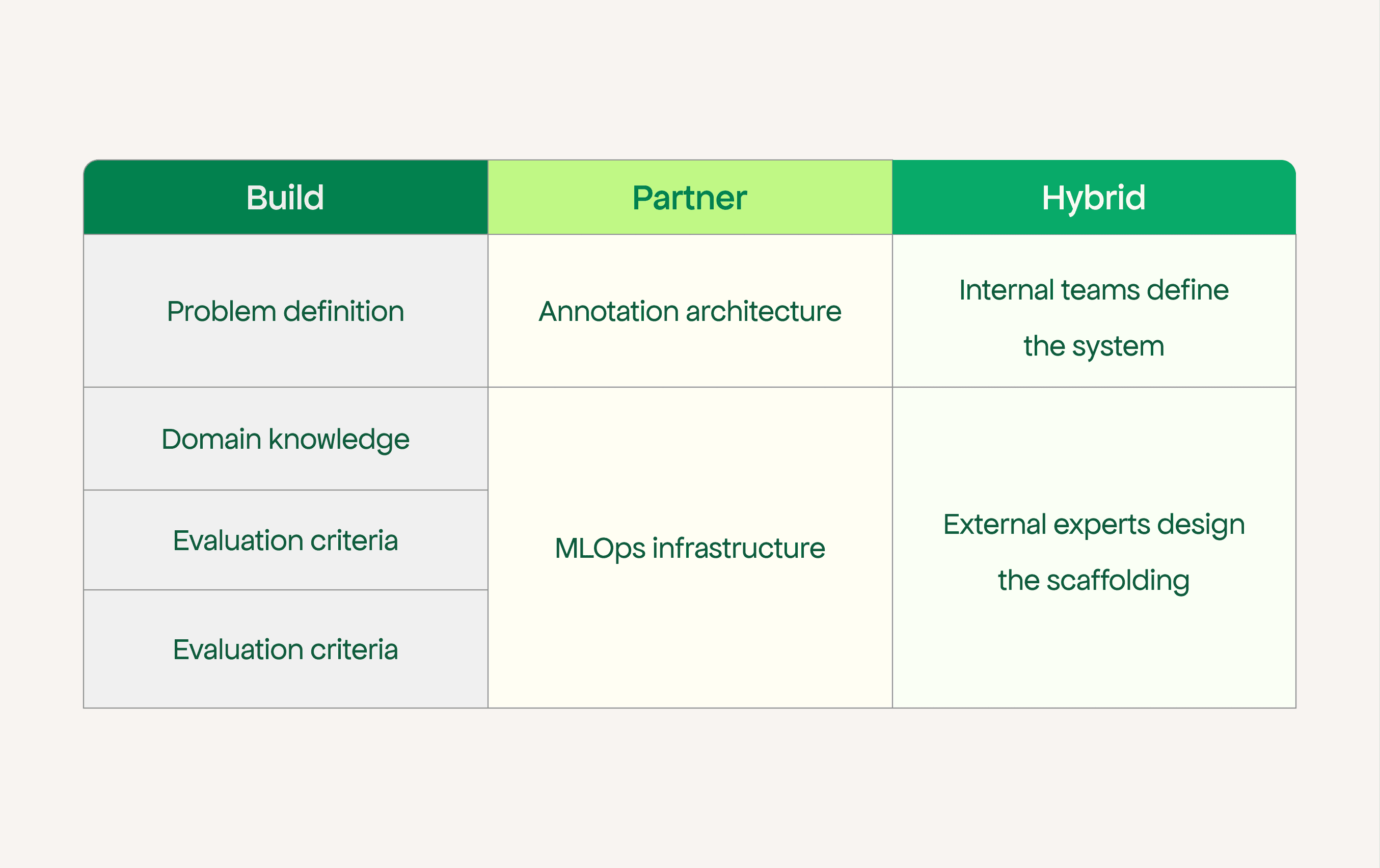
Build where domain knowledge is the edge. Problem definition, evaluation criteria, labelling standards, model direction — these belong inside the business.
Partner where prior experience is the edge. Annotation pipeline design, MLOps infrastructure, production deployment, monitoring — these are learnable, but not for the first time on a live project.
This is not a binary choice. Successful teams split ownership across layers deliberately, not by default.
The real risk is timing. Discovering the gap at month nine, after timelines have been committed to the board, costs significantly more than addressing it at month two.
Most AI projects do not fail at the model.
They fail at the data pipeline, the annotation process, or the production deployment — stages that look straightforward on a project plan and turn into six-month detours in practice.
The decision to build internally is usually made when the project looks like a modeling problem.
By the time it reveals itself as an annotation problem or a deployment problem, the decision has already been made and the timeline has already been communicated upward.

Whether you should build your AI system internally or partner with an implementation specialist comes down to a direct question: has your team taken an AI model from prototype to production before, or are you building that capability while building the product?
The two paths have very different risk profiles, and most teams only discover which one they are on around month five.
Building internally makes sense
Domain knowledge is the most important asset in most AI projects. It lives inside the business, in the people who know what a defect actually means, what a high-risk customer actually looks like, what the edge cases are that no vendor will anticipate.
Handing an AI project entirely to an external team risks producing a model that performs well in evaluation and sits unused in production because nobody trusts it or can explain it.
Long-term ownership matters too. A system only the vendor understands is a dependency, not a capability.
These are real arguments. The question worth examining is which parts of the build your team is genuinely ready for.
Where Internal AI Builds Break Down
1. The Annotation Problem
In industrial and enterprise AI projects, annotation is where internal timelines first break down. The reason is not technical. It is structural.
The people with domain knowledge to label data correctly are also running production. A quality engineer who can identify a critical defect is the same person responsible for a line.
Pulling them reliably into annotation sessions, week after week, without something else suffering, is difficult to sustain. So annotation happens in batches, by whoever is available, with whatever shared understanding exists at that moment.
Then annotation gets distributed across teams. Quality labels some samples. Production labels others. Engineering reviews batches when capacity allows. Nobody is wrong, exactly. But nobody is consistent.
Six months in, the training dataset contains tens of thousands of samples labeled by three different teams with three different mental models of the same label. Quality called it a reject. Production called it a rework. Engineering called it acceptable variation. The model trained on this data does not learn the defect. It learns the disagreement.

This is extremely difficult to fix retroactively. Retrofitting annotation architecture onto a dataset that was labeled without one usually means restarting the effort.
Teams that discover this problem at month seven are looking at month twelve before they have usable training data. That is the conversation nobody wants to have with the business sponsor.
The annotation architecture that avoids this must be designed before labeling begins.
What works instead:
Define label standards once with domain experts
Document edge cases explicitly
Use trained annotators instead of ad hoc labeling
Implement adjudication for conflicting labels
Route only ambiguous cases to senior reviewers
None of this is technically complex. It requires someone who has built annotation pipelines before to design it correctly. Teams doing this for the first time often do not know what the architecture should look like until they have already built the wrong one.
2. The Production Gap: Why Prototypes Take Four Months and Deployment Takes Eight
The second place internal builds consistently stall is the crossing from working prototype to production system.
Getting a model to perform well in a development environment is a different problem from making it reliable under real conditions.
Production means serving infrastructure, latency management under load, monitoring for drift, data pipelines that handle upstream failures without cascading, and a retraining process that does not require restarting the entire project when performance degrades.
Teams that have shipped web applications or data platforms have relevant experience. But production ML has failure modes those disciplines do not prepare you for.
Model drift is not a bug. Debugging degraded prediction quality means tracing a problem simultaneously through the data pipeline, feature engineering, and the training process. Standard observability tooling does not cover it.
The pattern is consistent: the prototype took four months. Production takes another eight.
The eight months was not in the original estimate. The business sponsor is now twelve months into a six-month project, and the explanation for how that happened is not a comfortable one to give.
What Partnering Actually Solves
An implementation partner is not there to replace your team.
They are most valuable where you are building capability for the first time:
Designing annotation pipelines
Setting up MLOps infrastructure
Handling deployment complexity
Implementing monitoring and retraining
Your team still owns the problem definition and model direction.
Over time, the goal is not dependence — it is capability transfer
A More Honest Framing
Every team eventually learns annotation architecture and production MLOps.
The only real question is when.
Before building → faster execution, predictable timelines
After building → rework, delays, and difficult stakeholder conversations
The difference is not technical ability. It is sequencing.
Signals Your Build May Need a Different Approach
These are specific, checkable conditions, not general warnings about AI project risk.
Annotation has been running for more than three months and inter-annotator agreement has not been measured. If the team cannot state the agreement rate, training data quality is unknown. Unknown data quality produces unpredictable models.
The production deployment architecture is still undecided. "We'll figure out the serving layer when we get there" is a plan that consistently costs more time than the original estimate assumed. Decisions deferred to the deployment stage are rarely faster to make under pressure.
The project has slipped once and the reason given was data quality. Data quality problems in AI projects compound. They require annotation architecture changes, and those changes are substantially faster to implement before labeling at scale has happened
The team's ML experience is in research or experimentation, not production systems. The skills required to get a model working and the skills required to make it reliable are not the same set. Recognising this early is not a weakness. Discovering it at month nine is expensive.
None of these signals mean the build decision was wrong. They indicate specific gaps in the current approach. Identifying them in month three is manageable. Identifying them after timelines have been committed to a board is a different conversation entirely.
The Only Variable That Actually Matters
Every team eventually learns annotation architecture and production MLOps. The question is not whether they will figure it out. It is when.
Teams that figure it out before they start building ship on the timelines they committed to. Teams that figure it out after six months of labeling or a prototype that will not scale restart significant portions of the work. The difference is not technical ability. It is sequencing.
The teams that consistently deliver production AI are not always the ones with the best engineers. They are the ones that knew where their experience stopped, got help at the right layers, and made that decision early enough to matter.
